

In Part 1 I wrote about enterprise IdPs (Azure AD, Okta, etc.) and how suspicious sign-in behavior can present itself. Now we turn to the cloud accounts themselves, which have their own native identities and access mechanisms in AWS, Azure, and GCP. Each cloud has its own primitives (AWS IAM users/roles/keys, Azure AD service principals/managed identities, GCP service accounts/workload identities), and attackers abuse them in different ways. Throughout this post I’ll emphasize a behavior-first detection approach: rather than writing platform-specific queries, we look for what adversaries do (their tactics and patterns) that cut across clouds. Building this personal understanding will allow us to paint a mental picture of how attackers navigate into our cloud environments. In practice this means focusing on higher-level “TTPs” (techniques) instead of low-level artifacts. As David Bianco’s Pyramid of Pain reminds us, indicators like static keys or IPs (atomic IOCs) are easy for attackers to change, whereas behavioral TTPs are at the top of the pyramid and much harder to evade. Our goal is to understand where to catch those high-level signals, including privilege chaining, anomalous resource launches, et cetera in any cloud platform.
Cloud-Native Identities and Access Models
Each cloud defines its own identity types and access controls, but the concepts overlap:
- AWS: Identities include long-lived IAM users (with permanent access keys) and ephemeral IAM roles (assumed by an identity via STS/Security Token Service). Roles are central: EC2 instances, Lambda functions, or federated users assume a role to get temporary credentials. Keys, policy attachments, and role assumptions all generate CloudTrail events we can monitor.
- Azure: Azure AD provides user and service principal identities. In practice we often see Managed Identities (the built-in service principals for VMs, App Services, Functions, etc.) and Service Principals (apps or scripts). These identities request OAuth tokens from Azure AD and then call Azure Resource Manager or other APIs. Role assignments (RBAC) tie identities to scopes. Notably, an Azure Managed Identity has no keys we manage; instead its use appears as an Azure AD token request followed by resource activity.
- GCP: Google Cloud has user accounts and service accounts (used by applications or VM workloads). Service accounts can have static keys (a risky practice) or use Google’s Workload Identity Federation to accept tokens from AWS/Azure or external IdPs. In GCP audit logs, actions by a federated service account include fields that identify the original AWS or Azure identity (e.g. an AWS ARN or Azure object ID). This lets us trace external identities into GCP.
To summarize, ideally we need to monitor IAM Users, Roles, Service Principals, Service Accounts, as well as the credentials and tokens they use. When an identity assumes a new role, creates a key, or escalates permissions, it generates cloud logs (CloudTrail, Azure Activity/Sign-in logs, GCP Audit Logs). The challenge is that each cloud’s logs have different schemas. By focusing on behaviors (what actions are taken in what context) we can write detection logic that is conceptually the same even as the raw log fields differ.
A Behavior-First Detection Approach
In detection engineering we can classify alerts as atomic (single-event, signature-like) versus behavioral (patterns indicating likely scenarios based on environmental context) versus correlation (linking events across data sources to craft a storyline). Atomic detections, such as firing an alert when a specific AWS API call is made, are easy to implement but only serve as a single item of a larger attack path story. We want to climb higher: catch sequences and anomalies that indicate intent, not just isolated API calls. For instance, creating an access key by itself is suspicious, but creating a key and then using it from an unusual IP or region is far more telling. Similarly, one-off events (like a one-time IAM policy change) are atomic alerts; behavioral series-based detections would look for an unusual series of operations (e.g. policy changes followed by resource deletion) or a single account exhibiting new actions.
To illustrate this we can think about this example: imagine a developer who has never spun up GPUs suddenly starts provisioning high-end GPU instances. A strictly “atomic” rule might only fire on an exact API call name, but a behavioral rule could say, “if User X provisions a GPU-enabled VM when this tenant has never had GPU VMs before, raise an alert.” Microsoft observed cases like this: compromised accounts had no history of creating compute resources and then suddenly launched GPU machines, presumably for crypto-mining. Catching that requires tying together the facts “this account has no past VM launches” with “this account just launched 10 GPU VMs”. That’s behavior-based. Likewise, AWS allows one role session to assume another (STS role-chaining). On its own that API call (AssumeRole) is atomic, but a behavioral view realizes: “Role A was assumed by Role B, and Role B has higher privileges than expected” – a classic privilege escalation pattern. The AssumeRole event is likely common in most corporate environments, but being able to tie context to the events and trigger investigation on certain conditions is a large step in a detection's maturity. Detecting that pattern is more valuable (and more painful for the attacker) than just watching for any AssumeRole call.
Whenever possible, we also use correlation to span multiple clouds or systems. For example, we may correlate an Okta login event (from Part 1) with a subsequent AWS role-assumption (from CloudTrail). This multi-log correlation is harder to set up and requires engineering effort to consolidate and normal log sources, but it lets us treat an SSO event as part of the kill chain. In this sense, our approach is still “detective”: we don’t assume we can see everything at the endpoint. Instead, we collect the cloud audit logs and hunt across them for the footprints of adversary activity, similar to how we’d build behavior detections on-prem, just adapted for cloud APIs.
Common Cloud Behavior Patterns to Monitor
In practice there are certain high-risk activities in the cloud that we watch for, regardless of platform. Naming conventions and slight service differences don't prevent threat actors from finding the same easy wins across different platforms. Here are examples of suspect behaviors and their rationale:
- GPU or high-end VM provisioning: As noted, provisioning GPU-enabled instances is rare unless you have legitimate compute workloads. Sudden or large-scale GPU VM launches (especially in regions or accounts where none existed) often indicate crypto-mining or other misuse. Watch for new accounts or roles that never launched VMs now spinning up multiple GPU instances.
- Resource usage spikes: Unexpected spikes in CPU, RAM, or I/O on a project or subscription can signal hidden crypto-mining or data exfiltration. For example, Microsoft warns that sharp utilization increases (without a valid business trigger) are a tip for cryptojacking (their terminology for cryptocurrency mining via compromised machines). Because cloud infra is elastic, attackers may push up against quotas, and these quota failures or rapid auto-scaling events can themselves be alerts.
- Excessive or anomalous API calls: A brand-new user or service account suddenly making a high volume of API requests, or calling services it never touched before, is very suspicious. The Wiz team notes that “anomalous API requests from a single user identity that deviate from typical usage patterns” are strong indicators of attack. For instance, a freshly-created service principal immediately calling dozens of IAM or EC2 APIs should be investigated as a potential automated attack.
- New credential creation: Unexpected creation of credentials , including but not limited to API keys, service account keys, and OAuth tokens, are a classic persistence technique. Attackers often steal an account and generate new credentials to maintain access. We monitor for access key or token creation events, especially if the creator identity is not normally a “credentials manager” in that environment.
- Role chaining or privilege hops: As mentioned, assume-role chains (AWS STS calls, GCP service account impersonation, Azure delegated role assignments) can be abused. If Role A (low privilege) is used to assume Role B (higher privilege), it could be an escalation. Rulehound provides an example that explicitly flags role chaining as a detection sign of privilege escalation. Similar ideas apply in GCP/Azure when one service account or managed identity is used to call an admin API.
- Cross-account or cross-subscription activity: Identity sprawl often means accounts have access in multiple environments. A user or service suddenly taking actions in another account or subscription (or assuming a role in another AWS account) is unusual. For example, if an IAM user is observed running EC2 commands in an AWS account it never used before, that warrants more attention.
- Security control tampering: Finally, we watch for disabling or altering logging/security configurations. Attackers with access to a privileged account may turn off CloudTrail, delete logs, remove MFA, or change RBAC assignments. While not cloud-specific “behavior,” these actions are anomalous and often combined with other attacks (e.g. “delete CloudTrail” followed by credential misuse). Attackers often perform actions like these as an anti-forensics measure, hoping to slow down defenders in noticing and then revoking their footholds.
The common thread is: we look for anomalies in account activity and resource patterns. By defining baseline behaviors and watching for deviations (new regions, new VM types, new APIs, surges in usage, etc.), we can apply similar logic in AWS, Azure, or GCP. The specifics of the log schema change, but the idea that user X does something unusual carries across.
The Impact of Federated Identities
Many organizations use SSO and federation so that enterprise IdPs (like Entra ID, Okta, or Google Workspace) authenticate users into AWS/Azure/GCP. This improves security, but it complicates our detections in two ways: logging and attribution. A federated login typically generates events in two systems. For example, an AWS user signing in via SAML triggers a CloudTrail AssumeRoleWithSAML event and an Okta/Entra login event. By default CloudTrail will record the STS call (with the IAM role ARN and a “RoleSessionName”), but it doesn’t inherently log the actual Okta username – unless that username was used as the session name. Thus, to tie that EC2 termination (for example) back to “Bob from example.com”, we must search the CloudTrail logs for the STS call and inspect the session name and ARN as Akshat Goel shows. In other words, AWS can capture the act of assuming a role, but making it mean “Bob did X” requires careful use of session names or extra logging.
In GCP, Workload Identity Federation is more explicit: the audit log entries include the original identity. For instance, Google’s docs show that for a federated token exchange, the log field principalSubject contains the AWS ARN or Azure managed identity ID that was used. That makes correlation easier: the cloud log tells us “this came from AWS ARN arn:blahblahblah:user/joe@example.com” or “Azure object ID xyz”. But again, we must enable the right audit logs (IAM admin read logs, etc.) to see it.
Entra is similar in principle: an Entra ID login shows up in the Sign-ins log (with the user’s UPN), and then resource access appears with a service principal or token. Correlation means joining the Entra Id sign-in with the Azure Activity log entries via the app or principal IDs. If federation is done via Azure AD’s built-in SSO, the token requests and role grants are all in Azure logs. In any case, federated identities mean you often have to stitch together two streams: the IdP’s login events and the CSP’s resource logs. If federation is wide-ranging (many IdPs, many platforms), you can easily end up with blind spots or missed links.
In practice, this impacts detection reliability. We must ensure our logging and SIEM account for it. It often means ingesting the identity provider logs alongside cloud logs so that a single alert can reference both sides of the login. It also means designing detections to account for indirect identity names. For example, if Okta was utilized to get an AWS token, the detection logic should include the Okta event and then correlate it to the resulting AWS activity (via that STS log entry). Failure to correlate properly can lead to missed detections: bob@example.com login in Okta and an EC2 API call as arn:aws:sts::123:assumed-role/RoleForSSO/bob@example.com. Treating these as separate makes the attack hard to spot. Whenever possible, we use fields like the role session name (which often includes the IdP username) or log metadata from federation to tie the pieces together.
In summary, federated SSO means “who did this?” can be an annoying two-part question. We must log and link the identity provider events with the cloud audit events. Many detection failures come not from missing a malicious API call, but from failing to recognize who made it. Robust correlation (joining on session IDs, ARNs, principal IDs, etc.) is essential when SSO is in play.
Managing Multi-Cloud Detection Complexity
One of the hardest parts of multi-cloud identity detection is simply the sprawl: dozens of services, logs, and potential alert sources to manage. In a large environment we might have hundreds of rules across AWS, Azure, and GCP. To avoid chaos, we can lean on structured frameworks and tools:
- Framework mapping: We can map each detection or rule to an ATT&CK tactic/technique. This gives us a common language across clouds. While achieving 100% coverage across known listed TTPs is borderline a meme since coverage != effectiveness, having a common repository of known methods to defend is incredibly helpful. Practically, we use the ATT&CK framework to ensure we’re not blind to entire categories of attacker behavior.

- Visualization tooling: We use visualization tools to highlight coverage and gaps in a manner that is easier to understand. For example, ATT&CK Navigator lets us color-code techniques we cover, and many SIEMs (like Datadog) have built-in ATT&CK maps that show which tactics have alerts assigned. This way we can glance and see, say, that we have dozens of detections for “Privilege Escalation” but none for “Account Manipulation”. Keeping that heatmap updated is crucial for multi-cloud parity. More mature teams can automate cataloging of their mapped rule TTPs and generate layers for an up-to-date visualization of their detection set.
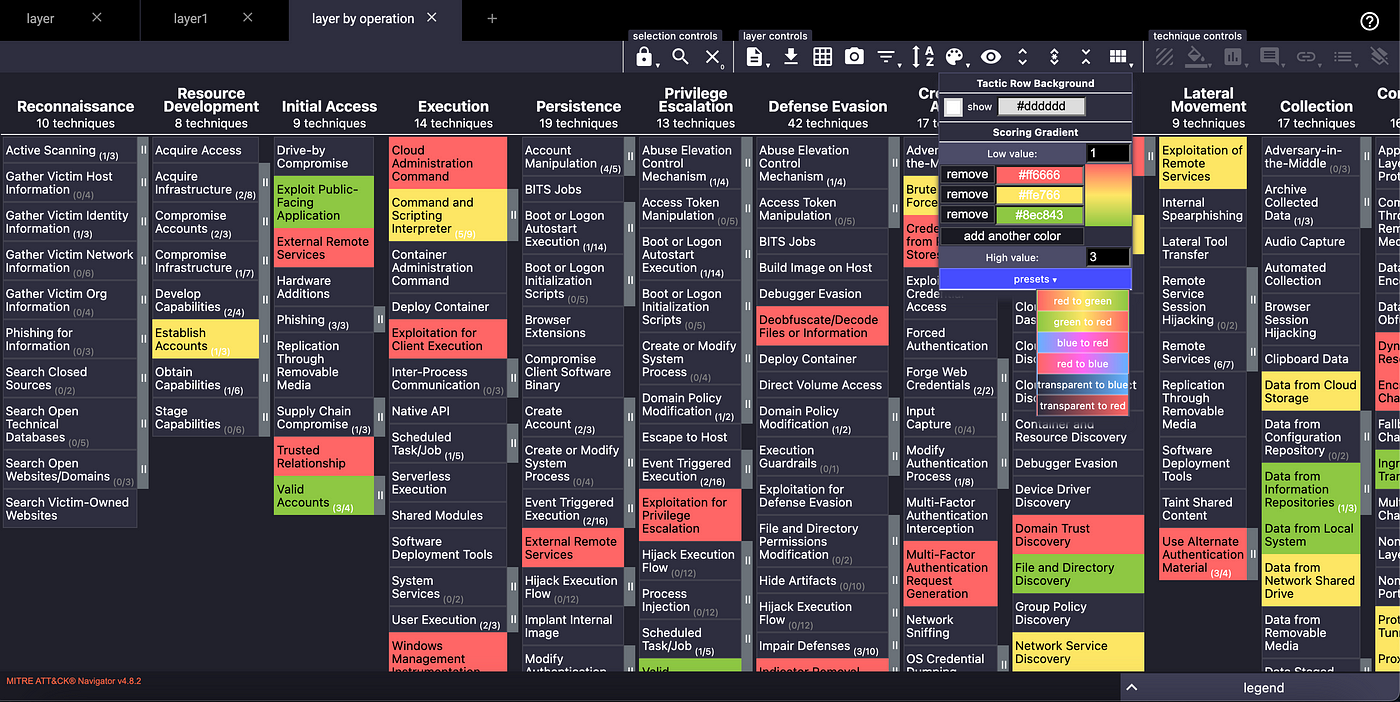
- Issue tracking (Jira, etc.): Each detection rule or playbook is tracked in a ticketing system. Many teams use Jira, creating an issue per detection use case or ATT&CK technique. For example, Atlassian’s security team builds a Jira ticket for every new detection play and uses Jira as the “single source of truth” for all their detection content. Tools like attack2jira automate populating a Jira project with all ATT&CK techniques as issues, so teams can attach our existing rules to the right technique in a structured manner. This ensures nothing falls through the cracks as the number of rules grows.
- Documentation and collaboration: Alongside tickets, we maintain a wiki or Confluence with detection logic notes, tests, and runbooks. Each detection links to relevant threat intel and log examples. This shared knowledge base means multiple engineers and analysts understand each rule’s purpose and context. I am partial to Palantir's Alerting Detection Strategy Framework
By combining these strategies above we make the complexity manageable. We can answer questions like “do we have a behavioral detection for suspicious GCP API calls similar to our AWS rule?” or “which rules cover the T1078 (valid accounts) technique across all clouds?”. In a well-ordered program, every ATT&CK technique we care about has at least one detection (atomic or behavioral) assigned, and every detection has a ticket and documentation.
Additionally, we lean on cloud-native threat tools to lighten the load. GuardDuty, Azure Defender (Microsoft Defender for Cloud), and similar services emit high-fidelity alerts on many identity abuses. Platforms like Wiz Defend (and others) also specialize in surfacing cloud-specific indicators and anomalous behaviors. Integrating these into our SOC reduces the need for us to hand-craft every rule from scratch. Still, we validate and often complement them with our own detections, especially for edge cases.
In the end, managing multi-cloud detection is as much a process problem as a technical one. It’s about clear ownership, up-to-date coverage matrices, and good hygiene (reviewing stale rules, tuning, etc.). We should know who is working each platform, what behaviors we’re watching for, and where any gaps remain. That structured approach pays off when an incident happens: the analyst can quickly see if this behavior is already covered by an existing detection or if we need to write a new one.
Detecting cloud identity abuse is challenging, but by thinking in terms of attacker behavior and using common frameworks, we can build a resilient, multi-cloud detection capability. In Part 1 we did this for IdPs and user sign-ins; here in Part 2 we extend it to the cloud platforms themselves, always aiming for the top of the Pyramid of Pain with our detections.
