

Cloud-first enterprises increasingly rely on Identity Providers (IdPs) like Azure AD and Okta as their new perimeter, but many SOCs are only just catching up. Without strong identity-focused monitoring, attackers can quietly slip in with stolen credentials or session cookies and move laterally between cloud apps. Cloud-based identities are an attractive target for a threat actors given their global accessibility and common misconfigurations. For example, Microsoft documented a real-world case where a trusted vendor’s account was compromised via an AiTM phishing campaign, which then pivoted into Business Email Compromise across multiple partner organizations. In short, identity is a battlefield that needs careful consideration and attention. If we are not seeing unusual sign‑in patterns (like impossible travel or anomalous device attributes), we are likely already missing these stealthy breaches.
The risk is real. Mandiant’s 2024 report noted that adversaries are now using “adversary‑in‑the‑middle” (AiTM) web‑proxy phishing to defeat MFA and blend in. Absent good coverage, dwell time remains high. The global median is still around 10 days, giving attackers a long runway. Early detection matters with this context. This post will walk through the building blocks of identity‑aware detections: what logs are available from each IdP, how to combine simple “atomic” detections with richer signals or risk scoring, and how to tie everything together to spot common compromise scenarios. I work daily with Google Chronicle as my SIEM, but the concepts in this article translate to any tooling that can aggregate and alert on patterns in logs. We’ll use conversational examples and YARA‑L detection snippets to illustrate each concept. By the end, you should have a mental toolbox for crafting cloud identity detections that real-world SOCs use to catch phishing, infostealers, brute‑force campaigns, and more.
Different Identity Providers
Azure AD: logs and their implications
Microsoft provided the statistic that over 95% of Fortune 500 companies utilize Azure for business, making understanding of it's authentication stack incredibly important for anyone looking to mature as an analyst. Azure AD (now Microsoft Entra ID) publishes rich sign‑in logs for each tenant. These logs include who signed in, how (web app, API, device, etc.), and what resource was accessed.. In other words, every successful or failed login can carry fields for the user account, application name, client app (browser/Exchange/etc.), IP address, geolocation, device ID, and error codes. With those fields, we can build detection rules to begin to detect anomalies. A few common examples include sign‑ins from rare countries, unfamiliar browsers, or unexpected app names.
Beyond raw logs, Azure AD also offers built‑in risk signals. For instance, Azure’s Identity Protection flags things like Atypical Travel or Unfamiliar sign‑in properties by comparing a user’s current login to their historical patterns. These Azure flags can spark alerts, but SOCs shouldn’t rely solely on them. Instead, use them as inspiration for your SIEM rules. For example, if a user with no previous logins from Asia suddenly signs in from Tokyo minutes after a New York login, that “impossible travel” gap should be caught by custom detection as well.
In practice, Azure sign‑in logs are a powerful dataset that is often underutilized by security teams. With a SIEM ingesting logs, we can easily query for useful information during triage like how many users signed into an app, how many failed sign‑ins occurred, or which operating systems were used. Understanding what information is important is a skill that is built with time, but we can use public repositories of queries to help break down the barriers. Once popular example of this is Ugur Koc's KQLSearch, a databsae full of community-submitted KQL (kusto query language) searches. Use tools like this to your advantage. For example, a rule might filter on app_display_name == "Office365" and city == "Moscow" for a US-based company to flag a login from an unexpected place. The key is understanding what each field in the Azure logs means (the “Who, How, What”) so you can write precise filters or baselines. Finally, remember that Azure AD also exposes audit logs for admin actions (user provisioning, policy changes, etc.), these can be useful for detecting post-compromise clean-up activities (like password resets or OAuth consent grants).
Okta/SSO: what gets logged, what gets lost
Okta’s System Log likewise captures authentication and user lifecycle events. That includes login successes/failures, application launches, factor challenges, and admin actions (adding users, MFA resets, etc.). For example, you’ll see events like user.session.start, user.authentication.sso, or user.password_authentication.failed if a login fails. SOC teams should pipe the Okta System Log into their SIEM to provide visibility and to start to create detections from these logs. With these events, you can detect things like multiple failed login attempts to Okta-protected apps, unusual factor rejections, or a spike in new application assignments, all of which can hint at misuse.
However, one major gap is downstream activity. If a user authenticates through Okta into a SaaS app (e.g. Salesforce via SAML), Okta’s logs will show only the Okta login event. Any activity inside Salesforce doesn’t appear in Okta’s logs. Similarly, Okta might show a user.session.end long after actual use of the session. In short, Okta logs cover the authentication step within Okta’s domain, but not what happens in the federated apps after. SOCs need to correlate Okta data with the target applications’ logs for full visibility.
Federation complexity: log gaps and architecture
Many enterprises use multiple IdPs in a chain. For example, some use Okta as the primary IdP, which in turn federates to Azure AD or Google Workspace. Others use on‑prem AD FS or Ping Identity. In such architectures, log coverage can fragment. Know your architecture. If Azure AD is configured as a federation with an on‑prem AD FS, raw Azure logs won’t show every detail of the user’s journey, only AD FS’s own logs do. Microsoft provides a solution: the Azure AD Connect Health agent can ingest AD FS sign‑ins into the Azure portal. As that docs page states, Connect Health lets you “integrate AD FS sign‑in events into the Microsoft Entra sign-ins report”. Without it, you may only see an opaque “Federated authentication” success or failure.
Likewise, if Okta is federated to an external IdP, or vice versa, you may lose visibility. Suppose a user logs in to Azure AD via Okta MFA: you’d see an Azure sign‑in event that was result = success (or failed) but the actual MFA validation occurred in Okta, and unfortunately that detail might not be in Azure’s logs. Or if Azure AD trusts Google as an external IdP, a Google login event needs to be captured by Google’s logs, not Azure’s. In practice, this means you should ingest and monitor all relevant logs: Azure sign‑in/audit logs, Okta system logs, and even on‑prem ADFS or SAML IdP logs. Only by correlating across the identity chain can you spot gaps. In summary, mapping your identity architecture is essential: know which events end up in which log store, and make sure your SIEM pulls them in.
Different Types of Detections
Atomic Detections
At the lowest level, many rules can be atomic: they look for a single specific indicator or simple pattern. I first come across this term when reading a blog post from Alex Teixeira from Detect FYI, he's written several incredibly insightful articles regarding detection engineering that I couldn't recommend more. He describes atomic alerts as:
Basically, that's a vanilla security alert — as we know it. It's an alert signal highlighting a particular pattern or a specific behavior observed in the network or in a host — plain and simple.
Malicious activity, whether a successful intrusion or just an attempt, is rarely comprised of a single action; it's a chain of events that typically leaves multiple traces in the logs. Breaking down each of these individual traces we can map events to a step on an attack path.
This is relevant when prioritizing detection efficiency using David Bianco’s “Pyramid of Pain,” which lists trivial indicators like hash values, IPs, and domains as the lowest in the detection engineer's priority. For example, a very simple YARA‑L rule might scan for a known malicious IP or user agent string in login events:
rule Malicious_Login_IP {
meta:
subject = "Acivity from Malicious IP"
description = "Detects when a activity occurs from a known malicious IP"
events:
$event.principal.ip = "210.XXX.XX.XX"
}
This rule fires (raises) on any activity from those IPs.. The defender advantage is this detection is straightforward to write; the attacker disadvantage is it’s trivial for them to switch IPs or domains to evade it. This matches the Pyramid of Pain concept: hash, IP, or domain indicators are easy for defenders to program but also easy for attackers to change.
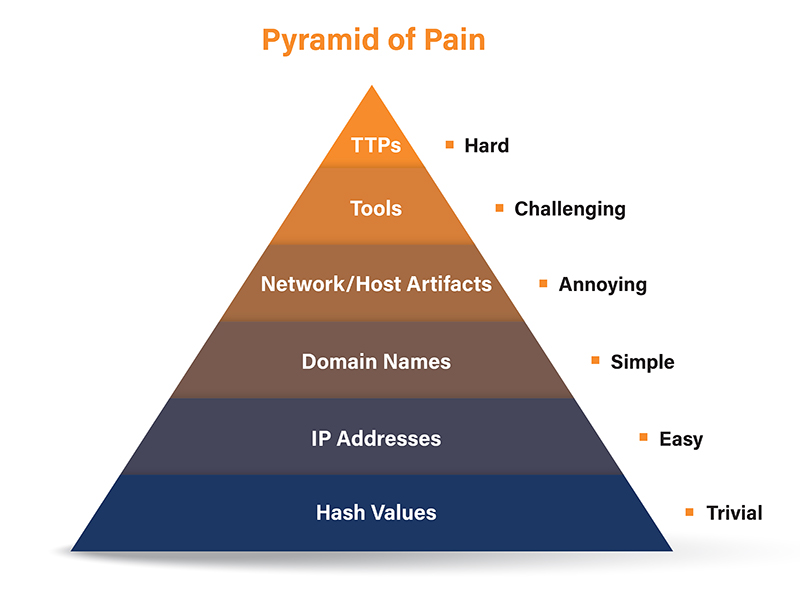
Detections at the top of the pyramid look for common attack paths of attackers and what logs they generate. For an example, it is a common post-compromise activity for a threat actor to add a new authenticator to an account as a form of persistence. In this case, we can build a low-severity detection triggering when any new authenticator is added to an Entra ID account. While this activity isolated is not malicious, it can be used in the context of other alerts such as unusual authentication patterns to correlate a larger incident.
rule entra_id_mfa_new_authenticator_app_added
{
meta:
subject = "entra id mfa new authenticator app added"
description = "This rule monitors and detects when a user adds new authenticator app for Azure AD Multi-Factor Authentication (MFA), indicating potential suspicious activity."
tactic = "Persistence"
technique = "Modify Authentication Process"
severity = "Low"
events:
$e.metadata.log_type = "OFFICE_365"
$e.metadata.product_event_type = /update user/ nocase
$user = $e.target.user.userid
$e.security_result.detection_fields.value = "Azure MFA StrongAuthenticationService"
condition:
$e
}
At the top of the pyramid are things like TTPs and behavior patterns, we can refer to more behavior-based detections as signals rather than simple IOCs. These are more robust to changes because attackers must modify their behavior to evade. In our identity context, a “signal” might be “impossible travel” or “new device + anomalous country login.” These aren’t single-field matches but rather anomalies. We illustrate these below.
Aggregation
To catch higher‑level signals, we often need aggregation and anomaly logic, basically UEBA in a rule engine. Instead of “just one login event,” we look at patterns over time or compared to a baseline. YARA‑L (Google Chronicle) supports this through outcome variables, windowing, and metrics. For example, one could count a user’s login volume over a week and flag if today’s count is 3× the 90th percentile of their baseline (calculated via the metrics function).
As an example, the Google SecOps community published a YARA‑L rule that calculates travel distance and speed between two login events. It uses math.geo_distance on the two sets of latitude/longitude, divides by the time difference, and computes KPH. The rule then assigns a risk score if the speed is beyond what is humanly possible (e.g. >1000 KPH). This is a classic risk indicator: it outputs a “risk_score” based on the severity of the anomaly, which an analyst can review. The detection looks something like this:
rule suspicious_auth_unusual_interval_time {
events:
$e1.metadata.log_type = "WORKSPACE_ACTIVITY"
$e1.metadata.event_type = "USER_LOGIN"
$e1.metadata.product_event_type = "login_success"
// match variables
$user = $e1.extracted.fields["actor.email"]
$e1_lat = $e1.principal.location.region_coordinates.latitude
$e1_long = $e1.principal.location.region_coordinates.longitude
// ensure consistent event sequencing, i.e., $e1 is before $e2
$e1.metadata.event_timestamp.seconds < $e2.metadata.event_timestamp.seconds
// check the $e1 and $e2 coordinates represent different locations
$e1_lat != $e2_lat
$e1_long != $e2_long
$e2.metadata.log_type = "WORKSPACE_ACTIVITY"
$e2.metadata.event_type = "USER_LOGIN"
$e2.metadata.product_event_type = "login_success"
// match variables
$user = $e2.extracted.fields["actor.email"]
$e2_lat = $e2.principal.location.region_coordinates.latitude
$e2_long = $e2.principal.location.region_coordinates.longitude
match:
$user,
$e1_lat,
$e1_long,
$e2_lat,
$e2_long
over 1d
outcome:
// calculate the interval between first and last event, in seconds
$duration_hours = cast.as_int(
min(
($e2.metadata.event_timestamp.seconds - $e1.metadata.event_timestamp.seconds)
/ 3600
)
)
// calculate distance between login events, and convert results into kilometers
// - math.ceil rounds up a float up to the nearest int
$distance_kilometers = math.ceil(
max(
math.geo_distance(
$e1_long,
$e1_lat,
$e2_long,
$e2_lat
)
)
// convert the math.geo_distance result from meters to kilometers
/ 1000
)
// calculate the speed in KPH
$kph = math.ceil($distance_kilometers / $duration_hours)
// // generate risk_score based on KPH, i.e., speed over distance travelled
$risk_score = (
if($kph >= 100 and $kph <= 249, 35) +
if($kph > 250 and $kph <= 449, 50) +
if($kph > 500 and $kph <= 999, 75) +
if($kph >= 1000, 90)
)
// change this according to your requirements
$risk_score_threshold = 90
condition:
$e1 and $e2 and $risk_score >= $risk_score_threshold
}In prose: “If the same user logs in from two IPs that are >1000 km apart within an hour, flag it.” We can then tune this for an acceptable level for our own environment, whitelisting common false positive reasons like corporate VPNs or traveling users on roaming networks.
Another example of using baseline deviations for detections is to find a user suddenly logging into many new apps. Outcome aggregation might compute metrics like mean, percentiles, or time-of-day histograms. One example metric from Chronicle might be “the user’s 90th percentile of successful logins per hour in the past month,” and flag if today’s hour exceeds that. This is a powerful way to catch deviations from baseline, and can be further built upon with even more complex detection logic outlined in another article from Alex Teixeira with the concept coined "Hyper Queries".
Correlation = Success
Finally, some of the best detections correlate across data sources. A pure identity log might not tell the whole story, but fusing auth logs with email or endpoint signals can crack cases. For example, suppose we see a surge of Office 365 mailbox forwarding rule creations among several users on the same day, plus simultaneous Azure AD logins from a rare country. Individually, each anomaly could be benign, but together they scream “mass compromise.” A YARA‑L composite rule could match events from two tables, apply logic to ensure the login event occurred before the mailbox rule creation, and generate a detection that would be more useful than either detection on their own. Here we’re requiring that the same user who just created a forwarding rule also logged in from an unfamiliar country. In practice, one would slide this over a time window (e.g. the rule and login within 30 minutes) and maybe raise only on multiple users.
This fusion of signals is the idea behind many cross-domain detections. For instance, Microsoft 365 Defender’s analytics correlate Defender for Cloud Apps and Defender for Endpoint signals. Using the Cloud Apps connector, it can trigger “Stolen session cookie was used” or “Possible AiTM phishing attempt” alerts. Similarly, Sentinel ships templates like “Possible AiTM phishing attempt against Azure AD”, “Multiple users forwarded to same destination”, or “Office Mail Rule Creation with suspicious archive move” (a proxy for credential compromise). The lesson: don’t silo email, endpoint, and identity logs. Write detections that “AND”s signals from different sources. A classic scenario is: user logs into Exchange Online from a new IP and within the next hour that user creates an inbox rule to forward mail. That combined rule will beat either indicator alone.
Understanding Types of Compromise
Phishing (AiTM focus)
Phishing is a perennial entry vector, but Adversary-in-the-Middle (AiTM) phishing has surged as a top threat. In AiTM attacks, the victim is tricked into logging into a real (or proxy) login page controlled by the attacker. The attacker sits between the user and the legitimate site, harvesting credentials and session cookies. Mandiant’s front-line report notes attackers are using web‑proxy phishing pages to bypass MFA. I've written about AiTM phishing before, this below blog post goes into more detail regarding what this looks like and how to mitigate these types of attacks.
In terms of detection, we look for unusual authentication signals. We already mentioned impossible travel, a classic marker and an essential detection cornerstone for identities. Other useful signals include Azure AD’s Unfamiliar sign-in properties, which flags logins outside a user’s typical profile. For example, if Alice normally logs in from Boston with Chrome, but one morning we see Alice log in from Singapore using Edge, that will either be flagged by Entra Risk or should raise an alert in our SIEM. We also monitor session cookie reuse. The Microsoft blog shows how to hunt for this: they identified stolen Office 365 cookies by finding SessionId values in the logs. In practice, one can JOIN the sign-in table on SessionId. For example, their KQL query below looks at the OfficeHome portal app (common indicator for AiTM phishing compromise)and finds where the same SessionId appears later in another country’s logins.
let OfficeHomeSessionIds =
AADSignInEventsBeta
| where Timestamp > ago(1d)
| where ErrorCode == 0
| where ApplicationId == "4765445b-32c6-49b0-83e6-1d93765276ca" //OfficeHome application
| where ClientAppUsed == "Browser"
| where LogonType has "interactiveUser"
| summarize arg_min(Timestamp, Country) by SessionId;
AADSignInEventsBeta
| where Timestamp > ago(1d)
| where ApplicationId != "4765445b-32c6-49b0-83e6-1d93765276ca"
| where ClientAppUsed == "Browser"
| project OtherTimestamp = Timestamp, Application, ApplicationId, AccountObjectId, AccountDisplayName, OtherCountry = Country, SessionId
| join OfficeHomeSessionIds on SessionId
| where OtherTimestamp > Timestamp and OtherCountry != CountryApplied as a detection, this rule fires when the same session ID appears in an OfficeHome login and another app login. In practice, you’d also check that the two events are close in time and have suspicious differences (e.g. different country). This type of rule can be difficult to recreate in Yara-L due to the lack of being able to store query results in a data table to be reused in the query later, but can be done via a mixture of reference tables and composite detections.
In short, for AiTM phishing we combine time/location anomalies (impossible travel, unfamiliar props) with cookie/session tracking (same session used twice) and portal usage clues (OfficeHome logins). We might also use risk scores from Azure: for example, an “Anomalous token” or “Session token replay” alert from Identity Protection is highly indicative. By fusing these signals (anomalous login, OfficeHome app use, and cookie reuse) we can catch the subtlety of AiTM.
Infostealers (corporate vs personal)
Infostealer malware (like RedLine, MetalStealer, etc.) can compromise corporate credentials by scraping browsers and files. When an infostealer hits a corporate machine, EDR or antivirus may detect a suspicious process and attempt to kill it. Tricky attacker tradecraft and evolving threats can mean that EDR protection isn't always enough, and on successful execution the stolen corporate credentials are often immediately used by the attacker via automated processes. In logs, we’d see the new IP or device for that account from the threat actor. For example, imagine a finance manager’s PC is infected: the next login for her corporate email might come from an overseas location or an unexpected device ID. One detection approach is to correlate endpoint alerts with identity logs: if EDR flags an infostealer and there’s a near-term sign-in from a new country for that user, raise a critical alert.
Distinguishing corporate vs. personal credential theft: if the target is a personal account (e.g. a personal Gmail) or originating on a personal device with corporate credentials synced, corporate controls may see little. But often attackers pivot from a personal account to corp (if MFA backup codes or passwords overlap), or a personal device login to corp VPN. In any case, look for login anomalies on corporate accounts. For instance, in Azure AD logs, a breached corporate user might trigger a “Token Issuer Anomaly” or unusual conditional access policy application. A hypothetical detection might watch for a user’s first successful login from a non‑corporate IP range plus common post-compromise patterns.
Even without EDR, just spotting a login from a new device or IP for a high-risk user (CFO, IT admin, etc.) could signal an infostealer. SOCs should also check for patterns like many account resets or data exfil from a user after unusual logins.
Credential-based attacks
Password spraying, brute force, and credential stuffing are noisy but predictable. Azure AD, Okta, and other similar identity providers will log every failed login attempt (each gets an event or error code). We can detect when failures spike by summarizing these events by a time window. For example, a YARA‑L rule for a password spray might look like: “Count sign-in failures by source IP or by user over a short time period..” In Chronicle one could write:
rule Suspected_PasswordSpray {
event:
$e.security_result.action = "SignInFailure"
$e.principal.ip = $ip
$e.principal.user.userid = $user
match:
$ip over 5m
outcome:
$distinct_user_count = count_distinct($user)
condition:
#e > 10 and $distinct_user_count > 5
}This fires if one IP had over 10 failures hitting at least 5 different accounts in 5 minutes. The idea is to catch a broad spray. Conversely, credential stuffing (using leaked lists) often looks like many accounts failing from many IPs, so you could invert it and count failures by user and distinct IPs. A simpler atomic case is: “One account has >10 failures in 10 minutes” (possible brute force). We can also watch for specific Azure AD error codes. For instance, code 50053 means “password expired/changed,” which sometimes appears during sprays.
Okta has a built-in feature called ThreatInsight that blocks IPs causing many login failures across Okta tenants. While that helps prevent wide-scale cloud attacks, SOCs should still monitor any sign-in failures, because not all threats are from known bad IPs.
In summary, credential‑based detections are often quantitative: thresholds and rates. Use SIEM dashboards to watch global login failure rates per hour, and write rules when they spike. A YARA‑L rule can easily count and compare against a threshold in its condition. Even a simple rule (failures > X in Y minutes) can stop a brute-force in progress.
Social engineering
Social engineering often leaves fewer clear technical traces, but it usually leads to downstream abuse. For example, if a user has been phished, the attacker might log into their mailbox and create an email forwarding rule to siphon mail. This action is logged. In Microsoft 365, the unified audit log records when a new Inbox Rule is created or when emails are forwarded. A detection rule could watch for suspicious mailbox rules, especially ones forwarding to external addresses. For instance, one could filter audit events for Operation == "New-InboxRule" and check if RuleType or MailboxActions includes a forward to an unknown domain.
Even in pure voice: if someone is socially engineered (e.g. CEO fraud via phone), you might only see aftermath like a rush of wire transfers. Those financial actions often have logs in ERP systems, but from a pure identity standpoint, we focus on anything in the identity stack: new MFA methods added, new admin role granted, or evidence of a user visiting a risky site. Unfortunately, many subtle cases rely on humans reporting strange requests or IT noticing unusual admin behavior. What can be logged includes MFA resets, OAuth grants for third‑party apps (e.g. “user consent to app”), and the standard “who changed what” in identity management. In practice, combine those logs with user reporting to catch social engineering.
Despite these challenges, remember: downstream actions are our canaries. Always monitor post-login changes: new inbox rules, permission changes, group additions, etc. Each of those is a cue to possibly rewind and inspect the user’s recent logins.
Resources
Being a serial collector of blogs and useful resources, here are some of my most-utilized things:

Detect FYI is an incredibly insight blog for Detection Engineering

Community-driven KQL query database, great for basing detection rules

Google's community repository for Yara-L rules
Sigma Rule Repository, very useful for finding ideas and things to implement
